Zipline in the Cloud
Thomas Wiecki

Source: http://www.mountainexposures.co.uk
About me
- PhD student at Brown University.
- Computational Cognitive Neuroscience.
- Quantitative Researcher at Quantopian.
- Optimizing trading algorithms.
Algorithmic Trading
- Algorithm makes trading decision automatically, based on external events (price, volume, twitter trends...)
Backtesting

Zipline http://zipline.io/
- Open-source backtester written in Python.
- Simulates real trading:
- Transaction costs
- Slippage
- Streaming of financial data:
- prevents look-ahead bias.
- portable to live-trading.
- Batteries included: moving average, alpha, beta, Sharpe ratio...
- Used in production on Quantopian.
Story-Time
Posted article on trading strategy on Quantopian forums:

In [9]:
from IPython.display import HTML
HTML("<iframe src=https://www.quantopian.com/posts/olmar-implementation-fixed-bug width=1100 height=350></iframe>")
Out[9]:
Here, I ported the algorithm to Zipline:
In [2]:
import zipline
STOCKS = ['AMD', 'CERN', 'COST', 'DELL', 'GPS', 'INTC', 'MMM']
class OLMAR(zipline.TradingAlgorithm):
def initialize(self, eps=1, window_length=5):
self.stocks = STOCKS
self.m = len(self.stocks)
self.price = {}
self.b_t = np.ones(self.m) / self.m
self.last_desired_port = np.ones(self.m) / self.m
self.eps = eps
self.init = True
self.days = 0
self.window_length = window_length
self.add_transform(zipline.transforms.MovingAverage, 'mavg', ['price'],
window_length=window_length)
self.set_slippage(zipline.finance.slippage.FixedSlippage())
self.set_commission(zipline.finance.commission.PerShare(cost=0))
def handle_data(self, data):
self.days += 1
if self.days < self.window_length:
return
if self.init:
self.rebalance_portfolio(data, self.b_t)
self.init = False
return
m = self.m
x_tilde = np.zeros(m)
b = np.zeros(m)
# find relative moving average price for each security
for i, stock in enumerate(self.stocks):
price = data[stock].price
# Relative mean deviation
x_tilde[i] = data[stock]['mavg']['price'] / price
###########################
# Inside of OLMAR (algo 2)
x_bar = x_tilde.mean()
# market relative deviation
mark_rel_dev = x_tilde - x_bar
# Expected return with current portfolio
exp_return = np.dot(self.b_t, x_tilde)
weight = self.eps - exp_return
variability = (np.linalg.norm(mark_rel_dev))**2
if variability == 0.0:
step_size = 0 # no portolio update
else:
step_size = max(0, weight/variability)
b = self.b_t + step_size*mark_rel_dev
b_norm = simplex_projection(b)
#print b_norm
self.rebalance_portfolio(data, b_norm)
# Predicted return with new portfolio
pred_return = np.dot(b_norm, x_tilde)
# update portfolio
self.b_t = b_norm
def rebalance_portfolio(self, data, desired_port):
#rebalance portfolio
desired_amount = np.zeros_like(desired_port)
current_amount = np.zeros_like(desired_port)
prices = np.zeros_like(desired_port)
if self.init:
positions_value = self.portfolio.starting_cash
else:
positions_value = self.portfolio.positions_value + self.portfolio.cash
for i, stock in enumerate(self.stocks):
current_amount[i] = self.portfolio.positions[stock].amount
prices[i] = data[stock].price
desired_amount = np.round(desired_port * positions_value / prices)
diff_amount = desired_amount - current_amount
for i, stock in enumerate(self.stocks):
self.order(stock, diff_amount[i]) #order_stock
def simplex_projection(v, b=1):
"""Projection vectors to the simplex domain
Implemented according to the paper: Efficient projections onto the
l1-ball for learning in high dimensions, John Duchi, et al. ICML 2008.
Implementation Time: 2011 June 17 by Bin@libin AT pmail.ntu.edu.sg
Optimization Problem: min_{w}\| w - v \|_{2}^{2}
s.t. sum_{i=1}^{m}=z, w_{i}\geq 0
Input: A vector v \in R^{m}, and a scalar z > 0 (default=1)
Output: Projection vector w
:Example:
>>> proj = simplex_projection([.4 ,.3, -.4, .5])
>>> print proj
array([ 0.33333333, 0.23333333, 0. , 0.43333333])
>>> print proj.sum()
1.0
Original matlab implementation: John Duchi (jduchi@cs.berkeley.edu)
Python-port: Copyright 2012 by Thomas Wiecki (thomas.wiecki@gmail.com).
"""
v = np.asarray(v)
p = len(v)
# Sort v into u in descending order
v = (v > 0) * v
u = np.sort(v)[::-1]
sv = np.cumsum(u)
rho = np.where(u > (sv - b) / np.arange(1, p+1))[0][-1]
theta = np.max([0, (sv[rho] - b) / (rho+1)])
w = (v - theta)
w[w<0] = 0
return w
Simplified version
In [ ]:
import zipline
class OLMARb(zipline.TradingAlgorithm):
def initialize(self, eps=1, window_length=5):
# How aggresive should we rebalance the portfolio
self.eps = eps
# How many days to compute the moving average over
self.window_length = window_length
# Include mavg transform into simulation. Makes it available
# in handle_data() below.
self.add_transform(zipline.transforms.MovingAverage, 'mavg', ['price'],
window_length=window_length)
def handle_data(self, data):
# Calculate how much each price diverged from its moving average
for stock in data:
deviation_from_mavg[stock] = data[stock].price - data[stock].mavg
# Calculate new portfolio allocation
desired_portfolio = current_portfolio + self.eps * deviation_from_mavg
# Rebalance portfolio
self.rebalance_portfolio(desired_portfolio)
Import data from yahoo finance.
In [3]:
start = datetime.datetime(2001, 8, 1)
end = datetime.datetime(2013, 2, 1)
In [4]:
data = zipline.utils.load_from_yahoo(stocks=STOCKS, indexes={}, start=start, end=end)
In [6]:
data.head()
Out[6]:
Let's see how it performs...
In [4]:
def run_olmar(eps=1, window_length=5):
olmar = OLMAR(eps=eps, window_length=window_length)
results = olmar.run(data)
return results.portfolio_value
In [12]:
results_eps2 = run_olmar(eps=2)
In [14]:
results_eps2.plot()
Out[14]:

Can we do better?
In [25]:
results_eps1 = run_olmar(eps=1)
In [26]:
results_eps2.plot()
results_eps1.plot(c='g')
Out[26]:

Parameter Optimization
Find parameter values eps and window_length that maximize objective function (i.e. cumulative wealth).
A solved problem?
Lots of optimization algorithms exist, for example:
- Hill climbing / Gradient ascent
- Convex optimization
Requirements and Properties:
- Continuous, differentiable.
- Convex
- Serial
Our objective function:
- Might be discontinuous,
window_lengthis discrete. - Might be multi-modal.
- Slow to compute -> need parallelism.
This is a more general problem, referred to as hyper-parameter optimization.
Support Vector Machine
- Parameters:
- Normal-vector of hyperplane $\leftarrow$ Convex
- Hyper-parameters:
- Soft margin parameter
C. - Kernel-type (RBF, polynomial) and associated parameter.
- Soft margin parameter

Computational Neuroscience
- Parameters:
- Weights $\leftarrow$ Continuous.
- Hyper-parameters:
- Network architecture (number of hidden units and layers)

Algorithmic Trading
- Parameter:
- Portfolio-allocation.
- Hyperparameters:
epsandwindow_length.
The problem thus far
- Large-scale models.
- Expensive to compute.
- No knowledge how objective function changes w.r.t. hyper-parameters.
Required
- Parallelism
- Global methods (not gradient-descent)
- Grid-search
- Bayesian Optimization
Parallel Computing in Python

Launch IPython cluster.
- command line: ipcluster
- IPython notebook
Connect to master
In [9]:
from IPython.parallel import Client
client = Client()
queue = client.direct_view()
print "Available workers: ", len(queue)
In [10]:
squared = queue.map_sync(lambda x: x**2, [1, 2, 3, 4])
print squared
%%px magic allows execution of cell on all nodes
In [3]:
%%px
import numpy as np
print np.linspace(0, 1, 5)
Great -- can run models in parallel on my laptop!

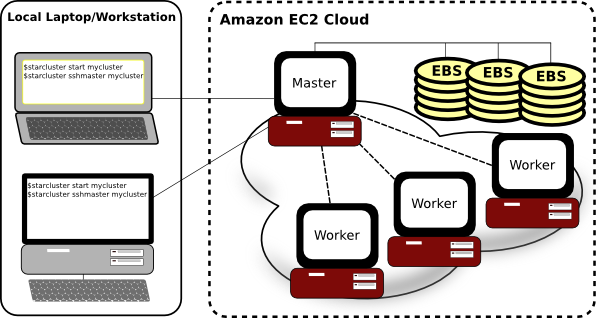
In [5]:
!cat ~/.starcluster/config_pydata
In [4]:
tic = time.time()
!starcluster -c ~/.starcluster/config_pydata start pydata
toc = time.time()
In [6]:
print "Took secs:", toc-tic
In [ ]:
from IPython.parallel import Client
client_sc = Client('/home/whyking/.starcluster/ipcluster/SecurityGroup:@sc-pydata-us-east-1.json', sshkey='/home/whyking/.ssh/mykey.rsa')
In [16]:
queue_sc = client_sc.direct_view()
print "Available workers: ", len(queue_sc)
In [2]:
queue_sc.map_sync(lambda x: x**2, [1, 2, 3, 4, 5, 6])
Out[2]:
Putting it all together.
In [12]:
eps = np.linspace(1.1, 40, len(queue_sc))
print eps
In [8]:
wealth = queue_sc.map_sync(run_olmar, eps)
In [9]:
plt.plot(eps, wealth)
Out[9]:

Optimization techniques

Bayesian Optimization via Gaussian Processes.

See Snoek, J., Larochelle, H., & Adams, R. P. (2012). Practical Bayesian Optimization of Machine Learning Algorithms, 1–12. Machine Learning; Learning. Retrieved from http://arxiv.org/abs/1206.2944

In [ ]:
# define a search space
from hyperopt import hp
space = hp.choice('a',
[
('case 1', 1 + hp.lognormal('c1', 0, 1)),
('case 2', hp.uniform('c2', -10, 10))
])
Conclusions
- Optimizing large-scale models is a different game.
- Technical solutions:
- IPython Parallel
- StarCluster
- Methodological solutions:
- Can borrow from Machine Learning.
Thanks!
Thomas Wiecki
email: twiecki@quantopian.com
Twitter: @twiecki, @quantopian
GitHub: twiecki