2016-2018 by Thomas Wiecki, updated by Maxim Kochurov
Original blog post: https://twiecki.github.io/blog/2016/06/01/bayesian-deep-learning/
Current trends in Machine Learning
There are currently three big trends in machine learning: Probabilistic Programming, Deep Learning and “Big Data”. Inside of PP, a lot of innovation is in making things scale using Variational Inference. In this blog post, I will show how to use Variational Inference in PyMC3 to fit a simple Bayesian Neural Network. I will also discuss how bridging Probabilistic Programming and Deep Learning can open up very interesting avenues to explore in future research.
Probabilistic Programming at scale
Probabilistic Programming allows very flexible creation of custom probabilistic models and is mainly concerned with insight and learning from your data. The approach is inherently Bayesian so we can specify priors to inform and constrain our models and get uncertainty estimation in form of a posterior distribution. Using MCMC sampling algorithms we can draw samples from this posterior to very flexibly estimate these models. PyMC3 and Stan are the current state-of-the-art tools to consruct and estimate these models. One major drawback of sampling, however, is that it’s often very slow, especially for high-dimensional models. That’s why more recently, variational inference algorithms have been developed that are almost as flexible as MCMC but much faster. Instead of drawing samples from the posterior, these algorithms instead fit a distribution (e.g. normal) to the posterior turning a sampling problem into and optimization problem. ADVI – Automatic Differentation Variational Inference – is implemented in PyMC3 and Stan, as well as a new package called Edward which is mainly concerned with Variational Inference.
Unfortunately, when it comes to traditional ML problems like classification or (non-linear) regression, Probabilistic Programming often plays second fiddle (in terms of accuracy and scalability) to more algorithmic approaches like ensemble learning (e.g. random forests or gradient boosted regression trees.
Deep Learning
Now in its third renaissance, deep learning has been making headlines repeatadly by dominating almost any object recognition benchmark, kicking ass at Atari games, and beating the world-champion Lee Sedol at Go. From a statistical point, Neural Networks are extremely good non-linear function approximators and representation learners. While mostly known for classification, they have been extended to unsupervised learning with AutoEncoders and in all sorts of other interesting ways (e.g. Recurrent Networks, or MDNs to estimate multimodal distributions). Why do they work so well? No one really knows as the statistical properties are still not fully understood.
A large part of the innoviation in deep learning is the ability to train these extremely complex models. This rests on several pillars: * Speed: facilitating the GPU allowed for much faster processing. * Software: frameworks like Theano and TensorFlow allow flexible creation of abstract models that can then be optimized and compiled to CPU or GPU. * Learning algorithms: training on sub-sets of the data – stochastic gradient descent – allows us to train these models on massive amounts of data. Techniques like drop-out avoid overfitting. * Architectural: A lot of innovation comes from changing the input layers, like for convolutional neural nets, or the output layers, like for MDNs.
Bridging Deep Learning and Probabilistic Programming
On one hand we have Probabilistic Programming which allows us to build rather small and focused models in a very principled and well-understood way to gain insight into our data; on the other hand we have deep learning which uses many heuristics to train huge and highly complex models that are amazing at prediction. Recent innovations in variational inference allow probabilistic programming to scale model complexity as well as data size. We are thus at the cusp of being able to combine these two approaches to hopefully unlock new innovations in Machine Learning. For more motivation, see also Dustin Tran’s recent blog post.
While this would allow Probabilistic Programming to be applied to a much wider set of interesting problems, I believe this bridging also holds great promise for innovations in Deep Learning. Some ideas are: * Uncertainty in predictions: As we will see below, the Bayesian Neural Network informs us about the uncertainty in its predictions. I think uncertainty is an underappreciated concept in Machine Learning as it’s clearly important for real-world applications. But it could also be useful in training. For example, we could train the model specifically on samples it is most uncertain about. * Uncertainty in representations: We also get uncertainty estimates of our weights which could inform us about the stability of the learned representations of the network. * Regularization with priors: Weights are often L2-regularized to avoid overfitting, this very naturally becomes a Gaussian prior for the weight coefficients. We could, however, imagine all kinds of other priors, like spike-and-slab to enforce sparsity (this would be more like using the L1-norm). * Transfer learning with informed priors: If we wanted to train a network on a new object recognition data set, we could bootstrap the learning by placing informed priors centered around weights retrieved from other pre-trained networks, like GoogLeNet. * Hierarchical Neural Networks: A very powerful approach in Probabilistic Programming is hierarchical modeling that allows pooling of things that were learned on sub-groups to the overall population (see my tutorial on Hierarchical Linear Regression in PyMC3). Applied to Neural Networks, in hierarchical data sets, we could train individual neural nets to specialize on sub-groups while still being informed about representations of the overall population. For example, imagine a network trained to classify car models from pictures of cars. We could train a hierarchical neural network where a sub-neural network is trained to tell apart models from only a single manufacturer. The intuition being that all cars from a certain manufactures share certain similarities so it would make sense to train individual networks that specialize on brands. However, due to the individual networks being connected at a higher layer, they would still share information with the other specialized sub-networks about features that are useful to all brands. Interestingly, different layers of the network could be informed by various levels of the hierarchy – e.g. early layers that extract visual lines could be identical in all sub-networks while the higher-order representations would be different. The hierarchical model would learn all that from the data. * Other hybrid architectures: We can more freely build all kinds of neural networks. For example, Bayesian non-parametrics could be used to flexibly adjust the size and shape of the hidden layers to optimally scale the network architecture to the problem at hand during training. Currently, this requires costly hyper-parameter optimization and a lot of tribal knowledge.
Bayesian Neural Networks in PyMC3
Generating data
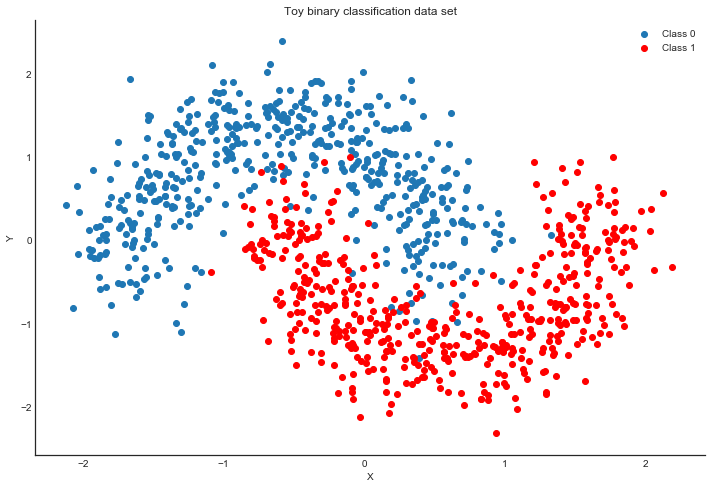
First, lets generate some toy data – a simple binary classification problem that’s not linearly separable.
%matplotlib inlineimport theanoimport pymc3 as pmimport sklearnimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom warnings import filterwarningsfilterwarnings('ignore')sns.set_style('white')from sklearn import datasetsfrom sklearn.preprocessing import scalefrom sklearn.cross_validation import train_test_splitfrom sklearn.datasets import make_moons
/Users/twiecki/anaconda/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
X, Y = make_moons(noise=0.2, random_state=0, n_samples=1000)X = scale(X)X = X.astype(floatX)Y = Y.astype(floatX)X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.5)
A neural network is quite simple. The basic unit is a perceptron which is nothing more than logistic regression. We use many of these in parallel and then stack them up to get hidden layers. Here we will use 2 hidden layers with 5 neurons each which is sufficient for such a simple problem.
def construct_nn(ann_input, ann_output): n_hidden =5# Initialize random weights between each layer init_1 = np.random.randn(X.shape[1], n_hidden).astype(floatX) init_2 = np.random.randn(n_hidden, n_hidden).astype(floatX) init_out = np.random.randn(n_hidden).astype(floatX)with pm.Model() as neural_network:# Weights from input to hidden layer weights_in_1 = pm.Normal('w_in_1', 0, sd=1, shape=(X.shape[1], n_hidden), testval=init_1)# Weights from 1st to 2nd layer weights_1_2 = pm.Normal('w_1_2', 0, sd=1, shape=(n_hidden, n_hidden), testval=init_2)# Weights from hidden layer to output weights_2_out = pm.Normal('w_2_out', 0, sd=1, shape=(n_hidden,), testval=init_out)# Build neural-network using tanh activation function act_1 = pm.math.tanh(pm.math.dot(ann_input, weights_in_1)) act_2 = pm.math.tanh(pm.math.dot(act_1, weights_1_2)) act_out = pm.math.sigmoid(pm.math.dot(act_2, weights_2_out))# Binary classification -> Bernoulli likelihood out = pm.Bernoulli('out', act_out, observed=ann_output, total_size=Y_train.shape[0] # IMPORTANT for minibatches )return neural_network# Trick: Turn inputs and outputs into shared variables. # It's still the same thing, but we can later change the values of the shared variable # (to switch in the test-data later) and pymc3 will just use the new data. # Kind-of like a pointer we can redirect.# For more info, see: http://deeplearning.net/software/theano/library/compile/shared.htmlann_input = theano.shared(X_train)ann_output = theano.shared(Y_train)neural_network = construct_nn(ann_input, ann_output)
That’s not so bad. The Normal priors help regularize the weights. Usually we would add a constant b to the inputs but I omitted it here to keep the code cleaner.
Variational Inference: Scaling model complexity
We could now just run a MCMC sampler like NUTS which works pretty well in this case, but as I already mentioned, this will become very slow as we scale our model up to deeper architectures with more layers.
Instead, we will use ADVI variational inference algorithm which was recently added to PyMC3, and updated to use the operator variational inference (OPVI) framework. This is much faster and will scale better. Note, that this is a mean-field approximation so we ignore correlations in the posterior.
from pymc3.theanof import set_tt_rng, MRG_RandomStreamsset_tt_rng(MRG_RandomStreams(42))
Average Loss = 120.67: 100%|██████████| 50000/50000 [00:47<00:00, 1055.45it/s]
Finished [100%]: Average Loss = 120.51
CPU times: user 40.6 s, sys: 17.8 s, total: 58.4 s
Wall time: 48.9 s
Performance wise that’s pretty good considering that NUTS is having a really hard time. Further below we make this even faster. To make it really fly, we probably want to run the Neural Network on the GPU.
As samples are more convenient to work with, we can very quickly draw samples from the variational approximation using the sample method (this is just sampling from Normal distributions, so not at all the same like MCMC):
trace = approx.sample(draws=5000)
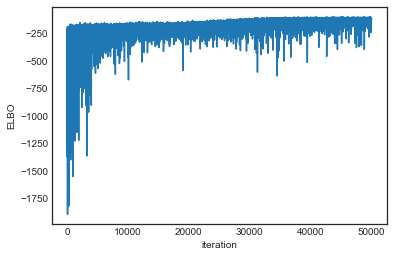
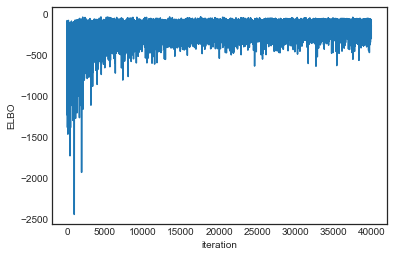
Plotting the objective function (ELBO) we can see that the optimization slowly improves the fit over time.
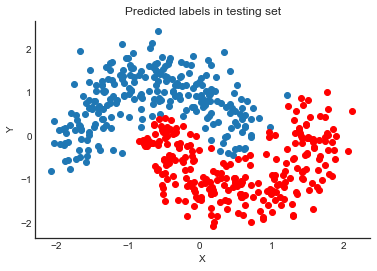
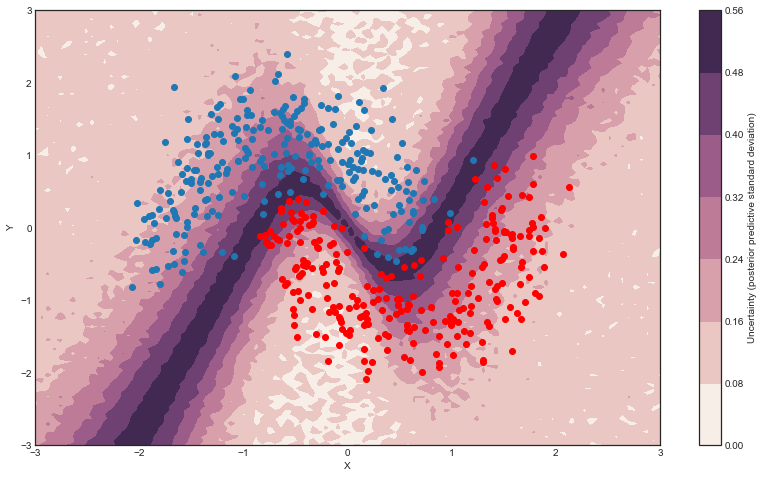
Now that we trained our model, lets predict on the hold-out set using a posterior predictive check (PPC).
# Replace arrays our NN references with the test dataann_input.set_value(X_test)ann_output.set_value(Y_test)with neural_network: ppc = pm.sample_ppc(trace, samples=500, progressbar=False)# Use probability of > 0.5 to assume prediction of class 1pred = ppc['out'].mean(axis=0) >0.5
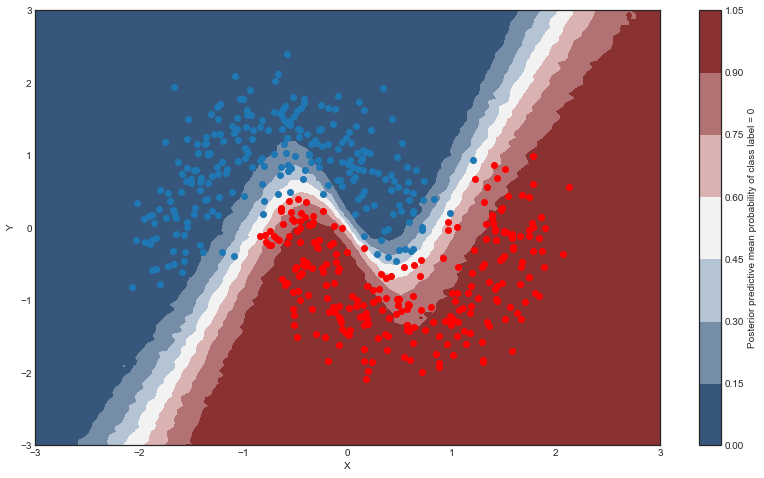
So far, everything I showed we could have done with a non-Bayesian Neural Network. The mean of the posterior predictive for each class-label should be identical to maximum likelihood predicted values. However, we can also look at the standard deviation of the posterior predictive to get a sense for the uncertainty in our predictions. Here is what that looks like:
We can see that very close to the decision boundary, our uncertainty as to which label to predict is highest. You can imagine that associating predictions with uncertainty is a critical property for many applications like health care. To further maximize accuracy, we might want to train the model primarily on samples from that high-uncertainty region.
Mini-batch ADVI
So far, we have trained our model on all data at once. Obviously this won’t scale to something like ImageNet. Moreover, training on mini-batches of data (stochastic gradient descent) avoids local minima and can lead to faster convergence.
Fortunately, ADVI can be run on mini-batches as well. It just requires some setting up:
As you can see, mini-batch ADVI’s running time is much lower. It also seems to converge faster.
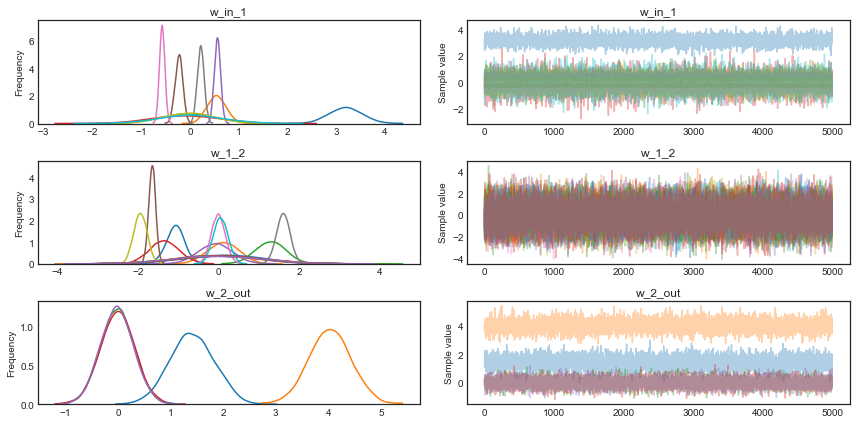
For fun, we can also look at the trace. The point is that we also get uncertainty of our Neural Network weights.
pm.traceplot(trace);
Summary
Hopefully this blog post demonstrated a very powerful new inference algorithm available in PyMC3: ADVI. I also think bridging the gap between Probabilistic Programming and Deep Learning can open up many new avenues for innovation in this space, as discussed above. Specifically, a hierarchical neural network sounds pretty bad-ass. These are really exciting times.
Next steps
Theano, which is used by PyMC3 as its computational backend, was mainly developed for estimating neural networks and there are great libraries like Lasagne that build on top of Theano to make construction of the most common neural network architectures easy. See my follow-up blog post on how to use Lasagne together with PyMC3.
You can also run this example on the GPU by setting device = gpu and floatX = float32 in your .theanorc.
You might argue that the above network isn’t really deep, but note that we could easily extend it to have more layers, including convolutional ones to train on more challenging data sets, as demonstrated [here](follow-up blog post on how to use Lasagne together with PyMC3.
I also presented some of this work at PyData London, view the video below:
Taku Yoshioka did a lot of work on the original ADVI implementation in PyMC3. I’d also like to the thank the Stan guys (specifically Alp Kucukelbir and Daniel Lee) for deriving ADVI and teaching us about it. Thanks also to Chris Fonnesbeck, Andrew Campbell, Taku Yoshioka, and Peadar Coyle for useful comments on an earlier draft.